데브옵스 엔지니어로 일을 하고 있지만 그래도 계속적으로 알고리즘이나 자료구조에 대한 부분은 항상 부족했다.
그래서 운영체제, 자료구조 등 정말 fundamental 한 공부부터 다시 시작해 보려고 한다.
자료구조를 먼저 시작을 해보자
이번 포스팅은 자료구조의 개념, 추상자료형, 알고리즘의 성능 분석 순으로 글을 전개해보고자 한다.
자료구조의 개념
Program Definition
A computer program is a collection of instructions that performs a specific task when executed by a computer.
즉, 컴퓨터에서 특정 작업을 수행하는 명령어들의 집합을 프로그램이라 한다.
Software
A collection of data or computer instructions , 프로그램보다 광의 개념으로
소프트웨어는 목적을 수행하기 위한 하나 또는 다수의 프로그램으로 구성되어있다
프로그램을 비롯해서 소프트웨어 개발과정에서 발생하는 문서, 데이터, 데이터베이스, 메뉴얼 등을 포함하는 포괄적인 개념이다.
자료구조와 알고리즘은 프로그램을 어떻게 효율적으로 잘 개발할 것인가의 문제와 연관되어 있다.
문제의 처리방식을 우리는 알고리즘이라고 하며, 이를 위한 처리대상을 자료라고 한다.
우리는 C, C++, Java, Python과 같은 언어로 프로그램을 작성하고 이를 컴파일한 후 기계어를 통해 처리결과를 얻게 된다.
예를 들어보자, 우리는 5명의 학생들의 성적의 평균을 구하는 프로그램을 만든다고 해보자
먼저 사용자에게 5명 학생의 성적에 대한 정보를 입력받아야 하고 그 후에 평균을 구해서 화면에 출력해 준다.
1. 사용자에게 입력받은 5명의 성적을 저장하는 방식
2. 평균을 구하는 공식
이 두가지를 해결해야 하는데 1번은 성적을 정수로 표현하기 때문에 정수형 그중에서도 Array로 저장하는 것이 효율적일 것이다. 따라서 1번을 자료구조의 범주라 볼 수 있다.
2번은 평균을 구하기 위한 함수를 만들어야 하는데 이러한 함수 즉, 로직을 우리는 알고리즘이라고 한다.
자료구조의 정의
자료구조란 문제해결을 위해 데이터 값들을 알고리즘들이 효율적으로 접근하여 처리할 수 있도록 체계적으로 조직하여 표현하는 것
즉, 아래의 질문에 대한 해결책을 제시하는 것이 자료 구조라 할 수 있다.
1. 데이터란 무엇인가?
2. 데이터는 어떠한 방식으로 컴퓨터에 표현되는가?
3. 데이터를 어떤 방식으로 처리하는 것이 보다 효율적인가?
자료구조의 분류
자료구조를 분류화 하면 아래와 같다.

다음번 포스팅부터는 단순 자료구조부터 비선형 자료구조까지 각각의 자료구조에 대한 설명을 해보고자 한다.
참고사항으로 최근에 파일구조는 자료구조에서 잘 쓰이지 않는다.
추상 자료형 Abstract Data Structure
추상화란?
추상화란 구체적인 대상에서 공통적인 측면이나 중요한 성질을 뽑아내여 표현하는 과정이다.
자세하고 복잡한 것은 숨기고 필수적이고 중요한 속성만을 골라 단순화시킴으로써 문제의 복잡성을 제어하고 코드 관리를 용이하게 한다.
예를 들어, 자동차 부품을 관리하는 프로그램을 짤 때, 우리는 추상화를 하기 위해 각 부품이 가지고 있는 공통적인 특성을 뽑아 추상화시킬 수 있다.
자동차의 메인 부품 part : 엔진 출력, 성능,
자동차의 타이어 부품 part : 타이어 브랜드, 사이즈
자동차의 외관 부품 part : 부품 색상, 부품종류, 사이즈
프로그램 (소프트웨어)의 추상화란?
프로그램을 구성하는 모듈의 사용방법과 세부적인 구현사항을 분리한다.
Abractraction = Data Abstraction + Procedural Abstraction
Data Abstraction : 데이터를 조작하기 위한 연산을 세부적인 구현 사항과 분리시켜 관리한다.
Procedural Abstraction : 함수 사용방법을 세부적인 구현사항과 분리한다.
Data Abstraction
1) 자료 Data : 프로그램의 처리 대상의 되는 모든 것, Value 를 의미하기도 함.
2) 연산 Operation : 어떤 일을 처리하는 과정으로 Operator(e.g. * + % -)에 의해서 수행됨
3) 자료형 Data Type : 처리할 자료의 집합과 자료에 대해 수행할 수 있는 Operator의 집합
Integer = {..,-9,... 0...9...} + {+ * / - %}
Abstraction Data Type
데이터 값의 집합 + 데이터에 적용되는 Operation 의 집합
A collection of data and set of operations on the data
e.g
| 자료구조 | Operation |
| List | Create an empty list Determine whether a list is empty Determine the number of items on a list Add an Item to the list Remove an item from the list Retrieve an item from the list Print the items on the list |
Interface
Abstraction Data Type 의 Operation 은 프로그램으로부터 자료구조를 분리시킨다. 즉, 인터페이스를 통해서 자료구조에 접근하게 하는 것이 좋은 설계의 예이다.
프로그램이 직접 자료구조에 접근해서 조작하는 것은 좋은 설계의 코드가 아니다.
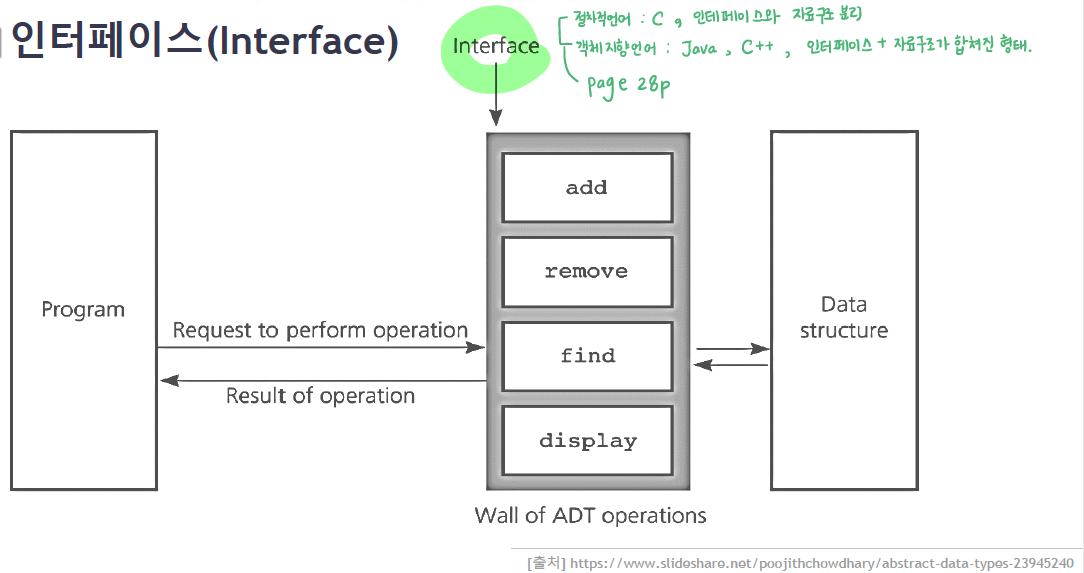
Expression of C language Abstraction Data Type
Interface : *.h 헤더 파일에 인터페이스 정의
*. c 파일에 실제 구현 내용이 담김.
사용자는 *.h 파일을 읽고 필요한 오퍼레이션을 *. c에서 호출해서 사용한다.
언어별 특징
C언어 : 절차적 언어, 추상자료형 (Class)는 지원하지 않는다.
C++, Java : 객체지향 언어 (OOP), Abstraction Data Type을 가장 큰 특징으로 한다.
const int MAX = 100; // this List can store maxium 100
class listClass{
private:
int Count; // the length of List
int Data[MAX]; // the data type of List
public:
listClass();
void Insert(int Position, int Item); //add data
void Delete(int Position); // delete data
void Retrieve(int Position, int *ItemPtr); //search data
}알고리즘 성능분석
잘 짜인 소프트 웨어란?
적은 자원을 사용해서 빠른 실행을 하는 것이 잘 짜인 소프트 웨어이다. 또한 적은 비용으로 개발하고 유지보수가 용이해야 한다.
Low resource requirement , Fast Running time, Development time and cost, Maintenance time and cost
알고리즘이란?
특정 문제를 해결하기 위해 기술한 일련의 명령문, 절차, 컴퓨터에 의한 자료처리 과정을 단계별로 기술한 것
알고리즘을 컴퓨터가 이해하고 실행할 수 있는 특정 프로그래밍 언어로 표현한 것을 알고리즘이라 한다.
좋은 알고리즘의 요건
1) 완전성과 명확성 : 수행 단계와 순서와 완전하고 명확하게 명세되어야 함, 순수하게 알고리즘이 지시하는 대로 실행하기만 하면 의도한 결과가 나와야 함
2) 입력과 출력 : 알고리즘이 처리해야 하는 대상으로 제공되는 데이터는 있을 수도 있고 없을 수도 있음, 입력 데이터를 처리하여 얻은 결과가 있어야 함
3) 유한성 : 언젠가는 반드시 종료한다 - 무한루프 돌면 안 됨
4) 효과성 : 모든 명령은 수행 가능한 것이여야 함
알고리즘의 표현
1) 자연어 이용
2) 순서도
순서도의 예시는 아래와 같다.
네모 칸은 입력을 말하고 마름모꼴은 조건문을 넣으면 된다.

3) 프로그래밍 언어
4) Pseudo- code : pseudocode is a plain language description of the steps in an algorithm or another system. Pseudocode often uses structural conventions of a normal programming language, but is intended for human reading rather than machine reading.
| Algorithm LargestNumber Input : A non-empty list of numbers L. Output : The largest number in the list L. largest <- L0 for each item in the list ( Length(L) >= 1), do if the item > largest, then largest <- the item return largest |
프로그램의 평가 기준
1) 원하는 결과의 생성 여부
2) 시스템에 따른 올바른 실행 여부
3) 프로그램의 성능
4) 사용법과 작동법에 대한 설명 여부
5) 유지 보수의 용이성
6) 프로그램의 판독 용이성
알고리즘의 성능평가
1) 복잡도 분석 = 성능 분석
컴퓨터 머신에 상관없이 프로그램을 실행하는 데 필요한 시간과 공간을 추정
복잡도 이론으로 표현 ( 공간 복잡도, 시간 복잡도)
2) 성능 측정 = 수행 시간 측정
컴퓨터가 실제로 프로그램을 컴파일하고 실행하는데 걸리는 정확한 시간을 측정, 컴퓨터 성능에 따라 결과가 달라질 수 있음.
3) 공간 복잡도 Space Complexity
저장 공간의 사용량을 말하는 함수
프로그램, 변수 등 고정적인 부분과 입력 데이터의 크기에 따라 변하는 부분으로 구성
S(p) = S(e) + S(c)
S(e) : 크기가 변하는 데이터 구조와 변수들이 필요로 하는 저장공간, 런타임 스택
S(c) : 고정된 공간 - 명령어 공간, 단순 변수, 복합 데이터 구조와 변수, 상수
e.g.
int sum(int list[], int n) {
int result = 0;
int i ;
for (i = 0; i < n; i++)
result = result +list[i];
return result;
}- 프로그램 영역 : 고정 사이즈 P
- 변수 n, result, i : 고정사이즈 3
- 변수 list [] : 저장 공간의 크기 n
- 전체 필요한 공간 = P + 3 + n
4) 시간 복잡도 Time Complexity
프로그램을 실행시켜 완료하는데 필요한 시간의 크기를 입력 데이터의 크기에 대한 함수로 표현
모든 명령어의 수행 시간이 같다고 보고 수행해야 할 명령어의 수를 함수로 표현
T(p) = T(e) + T(c)
T(e) : 명령문 하나를 실행하는데 걸리는 시간 * 실행 빈도수
T(c) : 프로그램을 컴파일하는데 걸리는 시간 (1번만 실행, 거의 무시하는 변수임)
1line : int sum(int list[], int n) {
2line : int result = 0;
3line : int i ;
4line : for (i = 0; i < n; i++)
5line : result = result +list[i];
6line : return result;
7line : }- 2 line, 3 line : 2번 실행
- 4, 5 line을 n 번 실행 : 2* n 번
- 6 line 을 1번 실행 : 1번 실행
2n +3 개의 문장이 실행됨
같은 작업을 하는 알고리즘에서는 명령어 수행 수 가 적은 같이 가장 빠르다 할 수 있다. 가장 대표적인 표현 법이 빅오 표기법이다.
5) Big-Oh
연산의 횟수를 대략적으로 표기한 것이다.
자료의 개수가 많은 경우에는 차수가 가장 큰 항이 가장 영향을 크게 미치고, 다른 항들을 상대적으로 무시될 수 있음
f, g 가 양의 정수를 갖는 함수 일 때, 두 양의 상수 a, b 가 존재하고, 모든 n>=b에 대해 f(n) <= a*g(n) 이면, f(n) = O(g(n))
빅오는 함수의 상한을 표시한다
규칙은 아래와 같다
- 상수는 버린다. f(n) = 3n +2 -> O(n)
- 상수만 있을 때는 시간 복잡도는 항상 1 f(n) = 100 -> O(1)
- 두 가지 항이 있을 때, 변수가 같으면 큰 것만 빼고 다 버린다. f(n) = 1000n^2 + 100n + 6 -> O(n2)
- 두가지 항이 있는데 변수가 다르면 놔둔다. O(N^2 +M)
| log n |
| n |
| n log n |
| n^2 |
| n^3 |
| 2^n |
| n! |

시간 복잡도가 1억 이면 이를 시간으로 환산하면 1초 정도이다.
지수 함수의 경우는 매우 빨리 증가하기 때문에 시간 복잡도가 높다.
대체적으로 시간 복잡도가 n log n 보다 크면 대개 실용적이지 못한다.
복잡도를 최대한 낮추는 방향으로 프로그램을 작성하도록 노력해야 한다.
'자료구조' 카테고리의 다른 글
| [자료구조 기초] Stack, 스택 (0) | 2021.04.14 |
|---|---|
| [자료구조 기초] 리스트, 선형 리스트, 단순 연결리스트, Linear List, Linked List (0) | 2021.04.13 |
| [자료구조 기초] structure, 구조체 (0) | 2021.04.13 |
| [ 자료구초 기초] Array, 배열 (0) | 2021.04.13 |
| [자료구조 기초] Pointer , 포인터 (0) | 2021.04.13 |